






Release Update V5.5.0
Das Release Update V5.5.0 ist da! Es gibt viele Verbesserungen für das Dashboard und für den Workflow. Schaut gern rein!

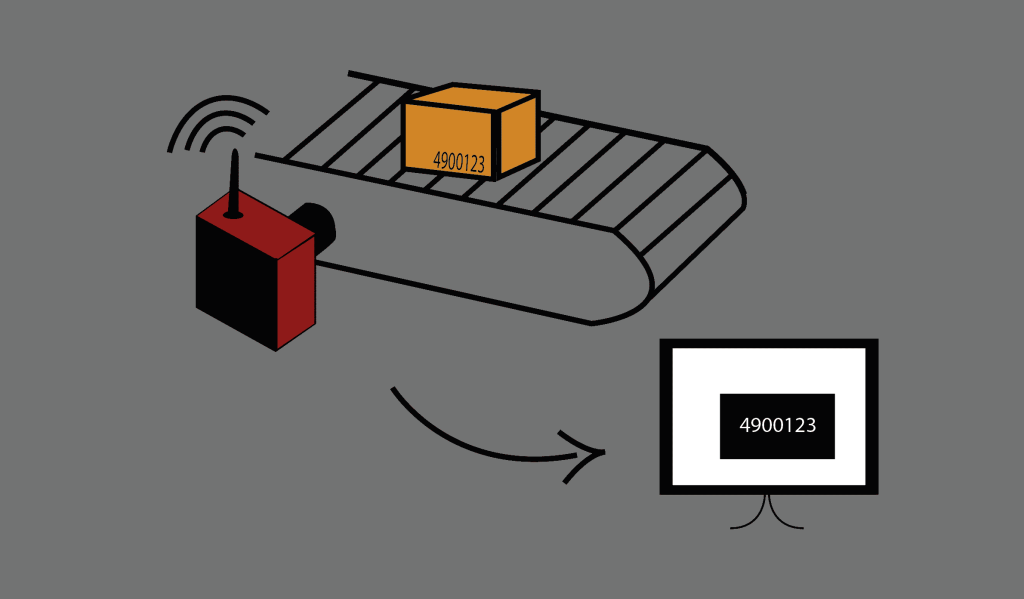
Industrielle Bildverarbeitung: Ein Einblick in die moderne Technologie 2024
Industrielle Bildverarbeitung: Seit vielen Jahren beschäftigen wir uns intensiv mit der industriellen Bildverarbeitung, doch was verbirgt sich eigentlich hinter diesem oft verwendeten Begriff?

Endlich: Die neue VIU2 PoE Kamera ist da!
Die VIU2 PoE Kamera ist da! Warum PoE ein wichtiges Feature ist, erfahrt ihr in diesem Artikel.
